System Design Notes
Requirements clarification
- Users/customers
- Who will use the system?
- How the sysem will be used?
- Scale - how to handle growing amount of data
- How many read queries per second?
- Hos much data is queried per second?
- How many video views are processed per second?
- Can there be spikes in traffic?
- Performance - how fast
- What is expected write-to-read data delay?
- What is expected p99 latency for read queries?
- Cost - budget for the system
- Should the design minimize the cost of development?
- Should the design minimize the cost of maintenance?
Functional requirements - API
- Start with specific function names
- Make several iterations to generalize API like the diagram below.

Non-functional requirements
- Scalable (tens of thousands of video views per second)
- Highly performant (few tens of milliseconds to return total view counts for a video)
- Highly available (survives hardware/network failures, no single point of failure)
- Consistency
- Cost
Architecture
Starting point

Data
What we store
Individual event vs aggregated data in real-time
- individual event includes timestamp, country, device type, operating system, etc.
- When we aggregate data, we calculate a total count per some time interval (e.g. 1 minute) and we lose details of each individual event. Question - why do we have to loes data for aggregate data? Is it through kinesis/kafka?
| --- | Invidividual events | Aggregated data |
|---|---|---|
| Pros | 1. Fast writes (2) Can slice and dice data however we need (3) Cal reclaculate numbers if needed. | (1) Fast reads (2) data is ready for decision making |
| Cons | (1) slow reads (2) Costly for a large scale (many events) | (1) Can query only the way data was aggregated. Question - why? (2) Requires data aggregation pipeline. We need to pre-aggregate data in memory before storing it in the database. (3) Hard or even impossible to fix errors why ? |
- Ask the interviewer about the expected data delay: time between when the event happened and when it was processed. If the latency is no more than several minutes, we must aggregate data on the fly (stream data processing). If several hours are okay, then we can store raw events and process them in the background (batch data processing).
Where we store
- Questions to ask
- How to scale writes?
- How to scale reads?
- How to make both writes and reads fast?
- How not to lose data in case of hardware faults and network partitions?
- How to achieve strong consistency? What are the tradeoffs?
- How to recover data in case of an outage?
- How to ensure data security?
- How to make it extensible for data model changes in the future?
- Where to run (cloud vs. on-premises data centers)?
- Cost of the solution?
SQL Database (MYSQL)
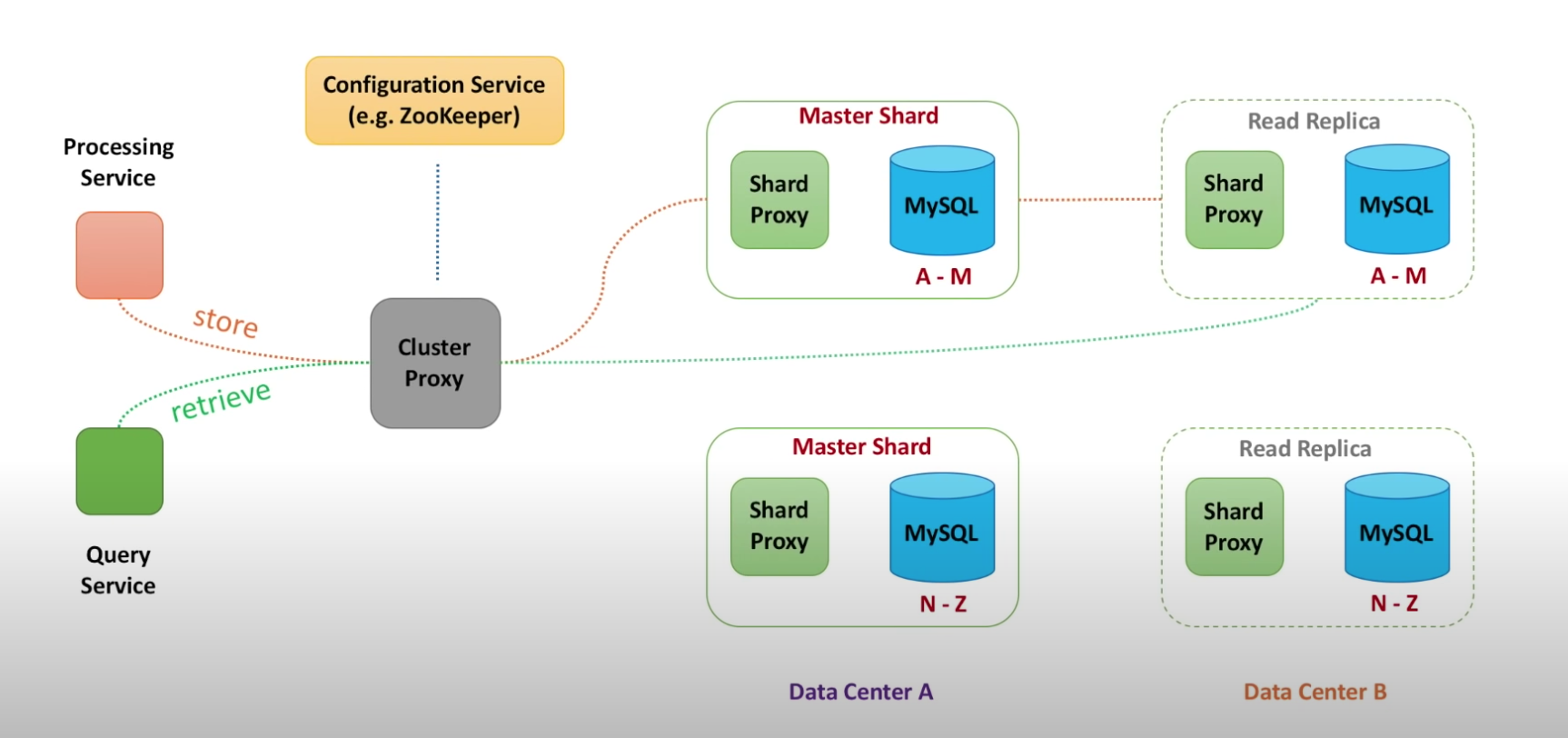
Scalability (Answer - partitioning) / Reliability (Answer - replicate data)
- Processing service - the service to store data in the database
- Qeury service - the service to retrieve data from the database
- Cluster proxy - knows about all databses and routes traffic to the correct shard. By having this layer, the processing and query services don't have to know everything about the database.
- Configuration service inside the proxy: Proxy needs to know when some shard dies or become unavailble due to network partition. If new shard has been added to the databse cluster, proxy should become aware of it. Therefore, configuration service does health checks to all the database shards.
- Shard proxy: cache query results, monitor database instance health, publish metrics, terminate queries that tke too long to return
Availability
- Master shard - writes go through the master shard
- Read replica (followers) - read go through both read replica and mastershard
- Put master shards and read replica in different data centers so if the whole data center goes down, we still have a copy of data available.
- Eventual consistency - With leader/follower paradigm, different users see different total count for a video. This inconsistency is temporary, over time all writes will propagate ot replicas.
Consistency
- Eventual consistency
Speed
- Keep things in memory
- Minimize disk reads
NoSQL database (Cassandra)
- Cassandra's read and write throughputs increase linearly as new machines are added.
- MongoDB is a document-oriented database and uses leader-based replication.
- HBase is a column-oriented data and uses leader-based replication.
Availability
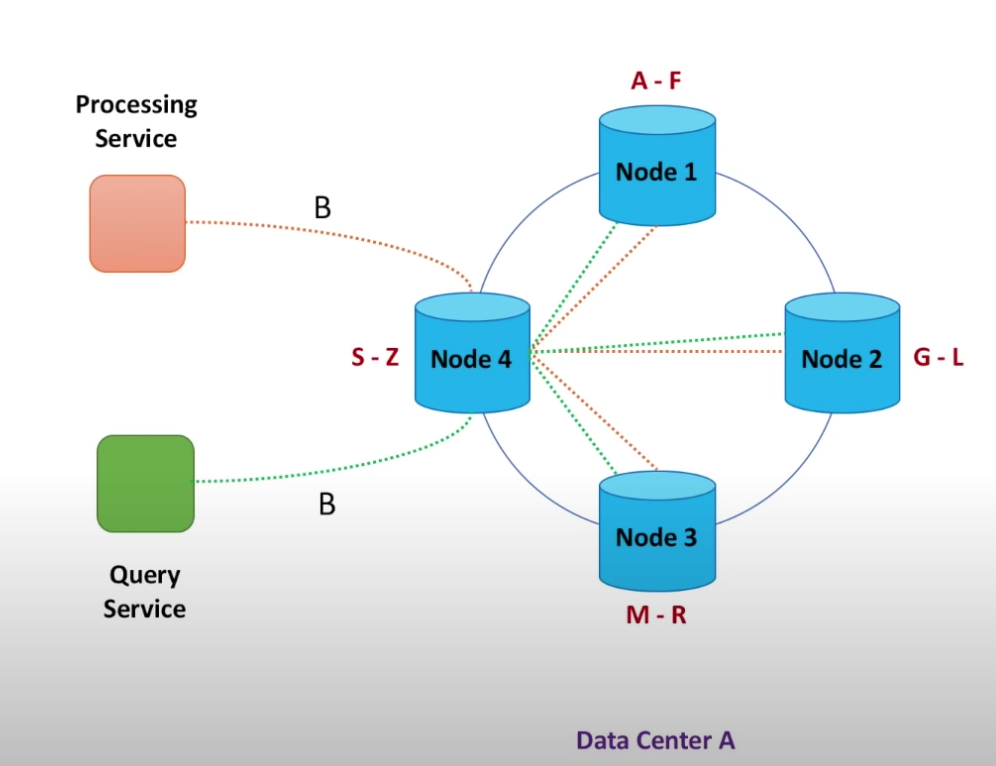
- Gossip protocol - Instead of having the configuration service that knows everything about all other databases, the nodes themselves knows about maximum 3 other nodes. Soon, the information about every node propagates.
- Quorum - A quorum is the minimum number of votes that a distributed transaction has to obtain in order to be allowed to perform an operation in a distributed system.
- Quorum reads/writes - query from 3 out of 5 nodes and get votes on which data to read or where to write to.
Consistency
- Eventual consistency
Processing Service
Questions
- How to scale?
- How to achieve high throughput?
- How not to lose data when processing node crashes?
- What to do when database is unavailable or slow?
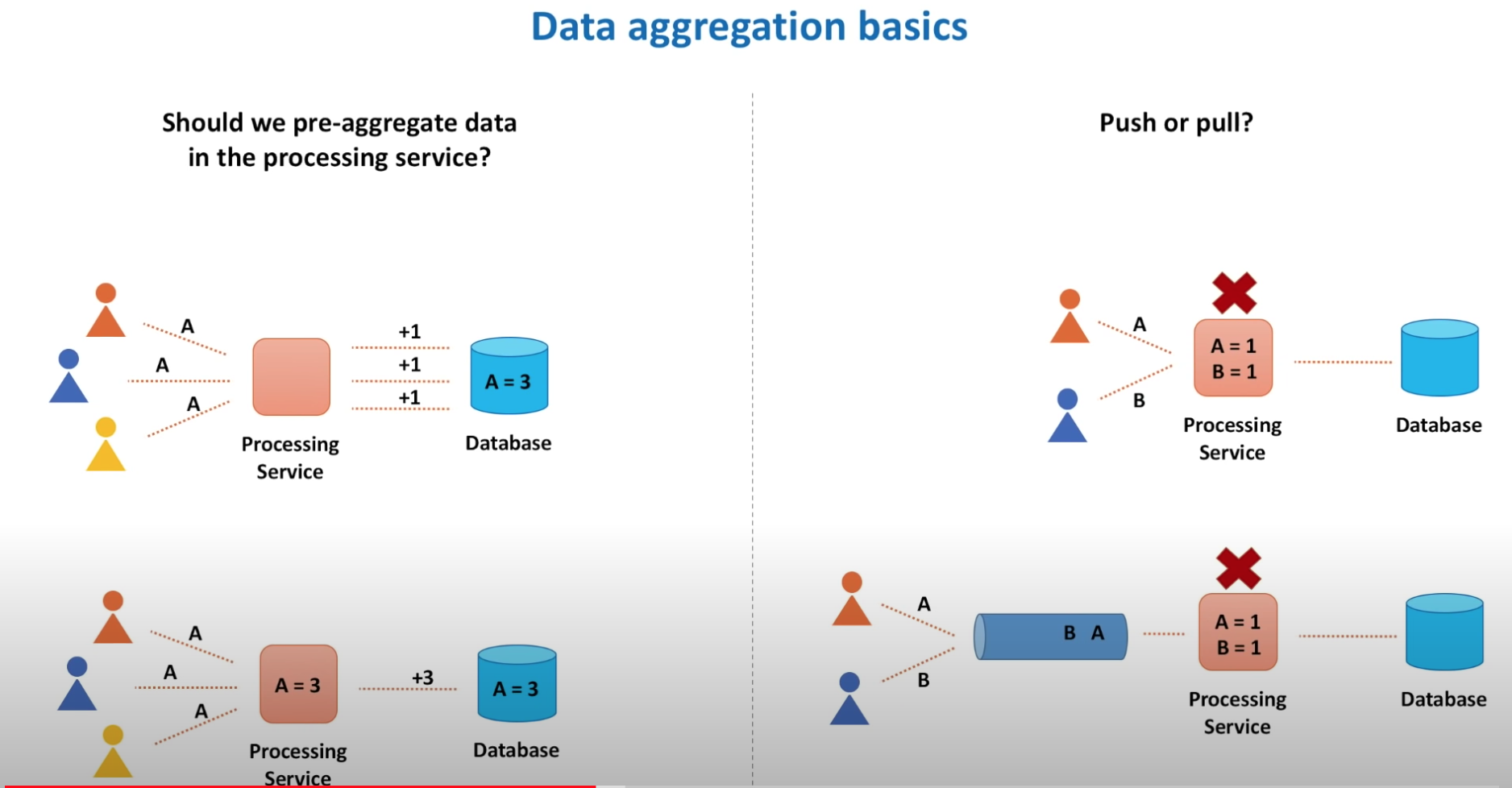
- The second option of saving conuters in the memory is better
- Question - is pull always better than push?
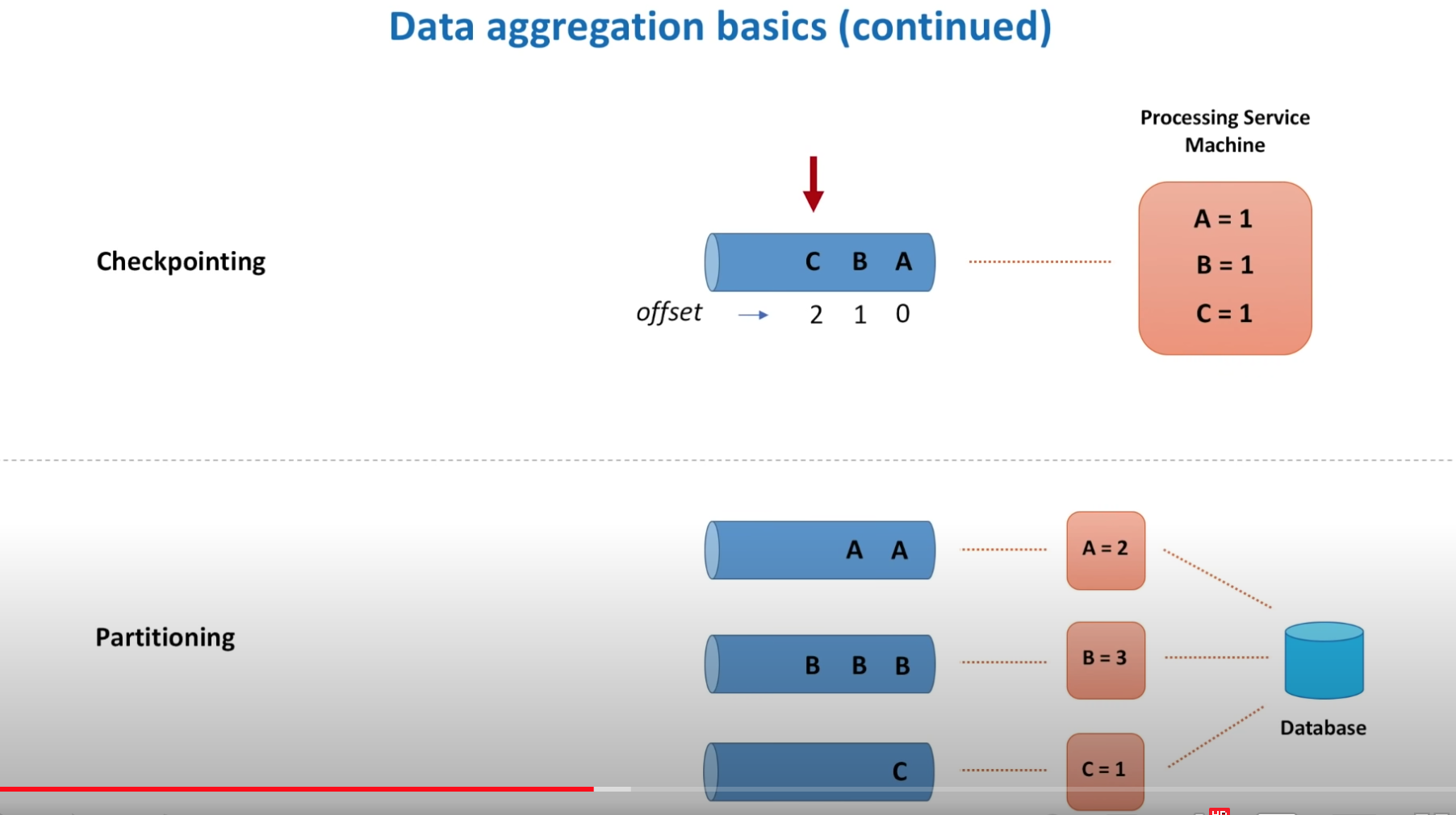
- Checkpointing is if a queue or node fails, another machine can pick up the job from the checkpoint.
- Partitioning - events are partitioned so they can be processed distributedly.
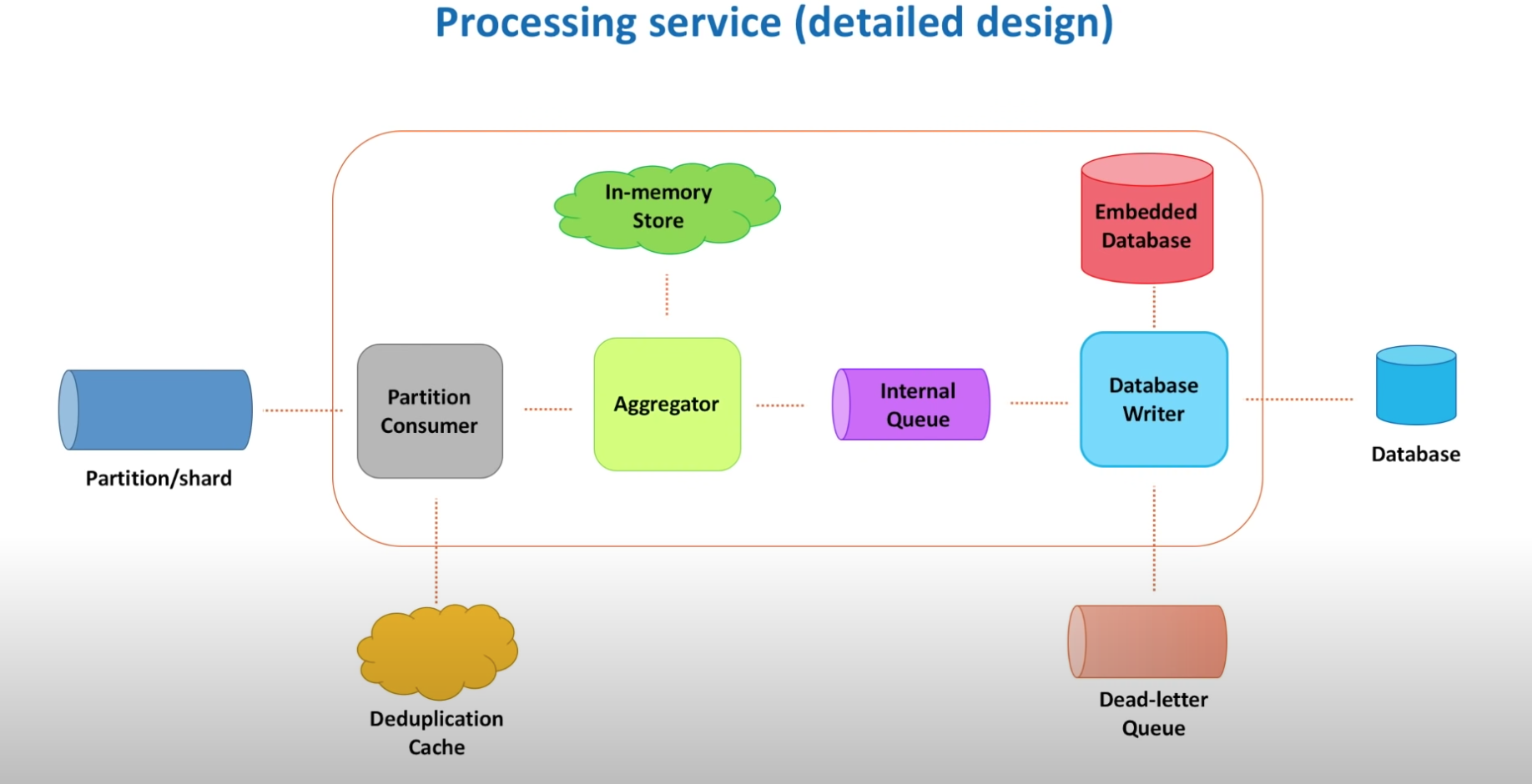 Question - does streaming events involve video live streaming?
Question - does streaming events involve video live streaming?
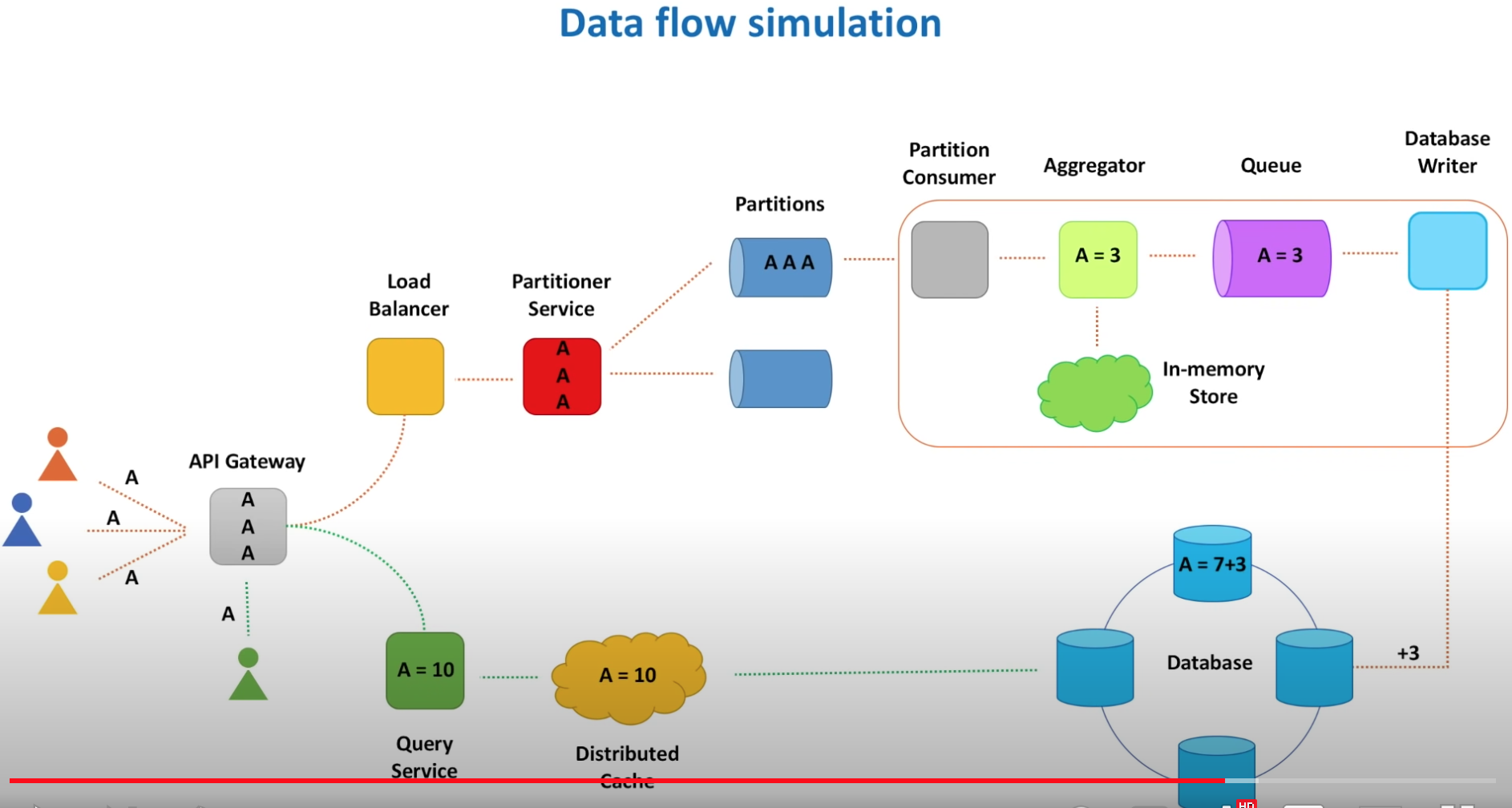
- Parition consumer - it converts byte array into the actual object. Maintains TCP connections. Single-threaded component. If this component is made multi-threaded, checkpointing becomes difficult and hard to preserve order of events.
- Deduplication cache - partition consumer does deduplication cache to remove duplicate data that has arrived to the partition.
- Aggregator - aggregates view counts in the hashtable in-memory. When it creates a new hashtable to do further job, it sends the old hashtable to the internal queue for further processing
- Internal queue - Processing of the events. Another queue is added so that we can separate aggregation of the events and processing the events.
- Database writer - single threaded or multithreaded components. It sends the aggregated data to the database.
- Dead letter queue - if database becomes slow, db writer can push letters to the dlq. And there's a separate process that reads from this queue to send to the db.
- Data enrichment - An alternative to DLQ. Saving undelivered message on the disk of the processing service
- Embedded database - event comes with minimal information. If you want to fetch detailed information with that event, you can use the local database inside the processing service. It has to be local to avoid remote calls.
- State store - in case in-memory aggregated data is lost, store in-memory data to a durable storage. (Question - is this storage database? or just any saving on disk?)
Data ingestion path
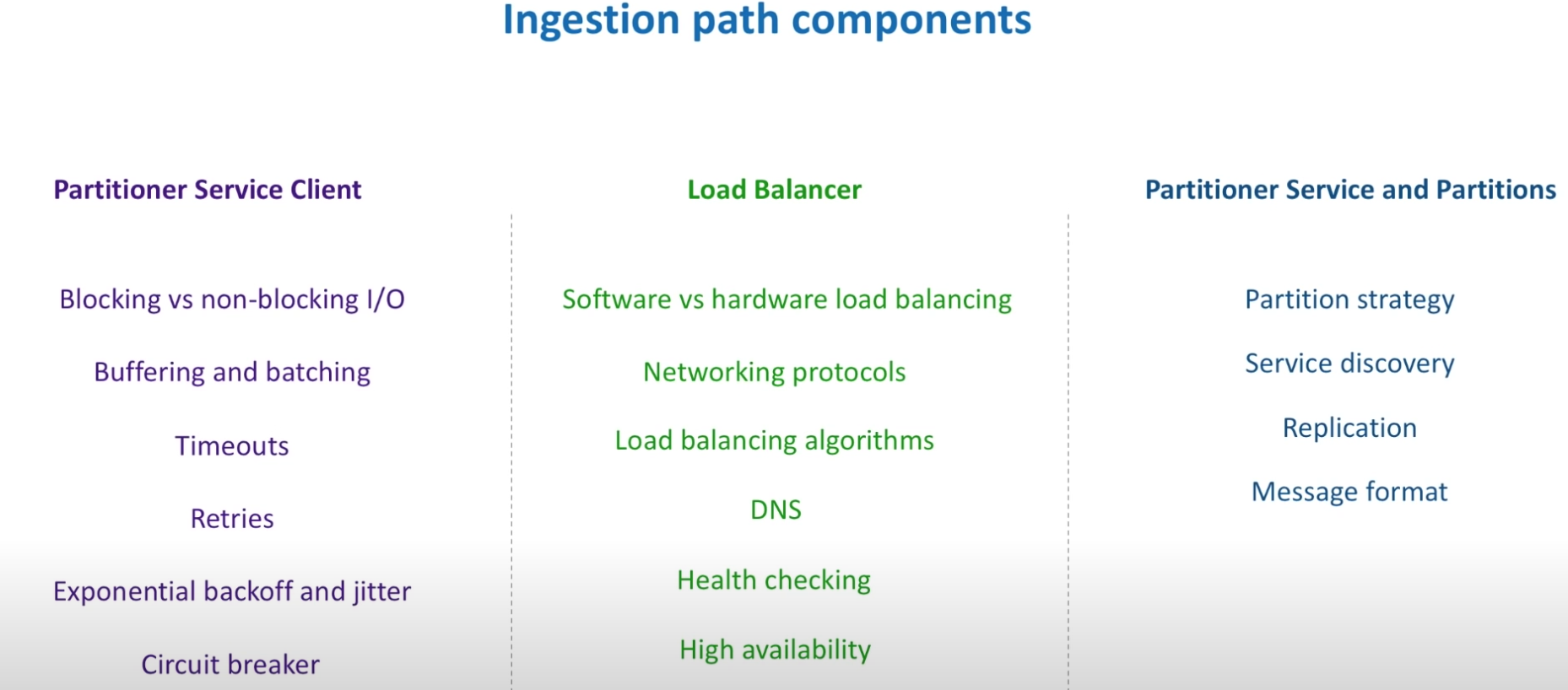
- API Gateway - it represents a single-entry point into a video content delivery system.
Partitioner service client (question - is it API gateway?)
- Blocking vs. nonblocking (question - what are some use cases to use blocking IO?)
- Timeouts - connection time out (how much time a client is willing to wait for a connection to establish 10 milliseoncds), request timeout (latency of 1 percent of slowest requests)
- Retries - exponential backoff (wait longer with every retry attempt) and jitter (adds randomness to retry intervals to srpead out the load)
- Circuit breaker pattern - how many errors have failed and stop calling the downstream. It makes the system more difficult to test.
Load balancer
- DNS - it maintains the list of domain names and translates to the IP addresses
Paritioner service and partitions
- Partition strategy - (hot-partition) based on the time
- question - what is client-side server discovery pattern?
Rollup count
- 1 minute becomes 1 hour then it becomes 1 day worth of data
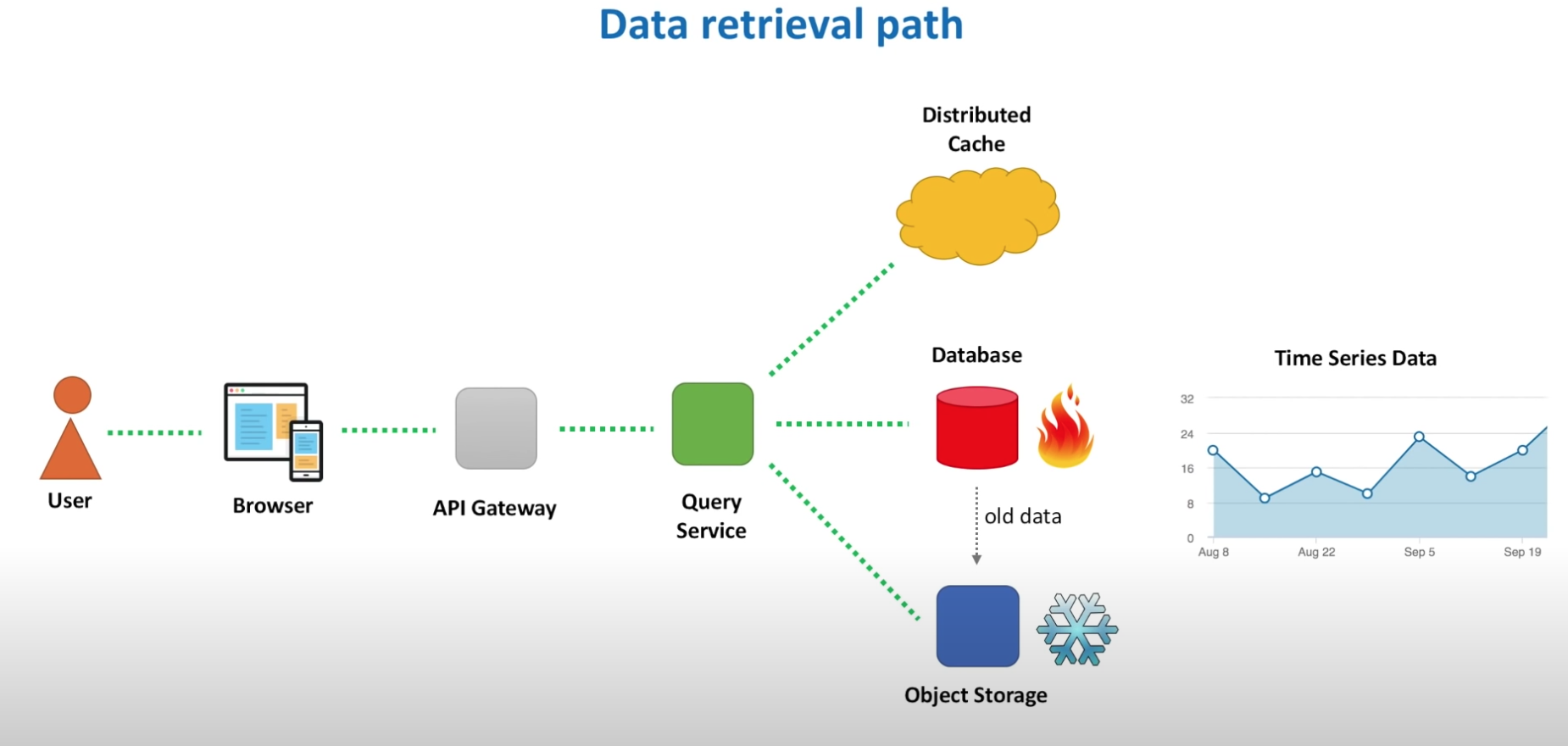
Hot storage vs. Cold storage
Hot storage - fast acces. cold storage - slow access