Design Netflix recommendation
Design a system to recommend a list of movies for Netflix users.
Requirements clarification
- Users/customers
What are we trying to give the users that they don't already have? The users just watch Netflix movies by manual searching and there's no recommended videos section.
How will the system be used? Open the app and have videos available for people under the recommended video section.
Who will use the system? 77 million users in the US and Canada
How do I know if the system works? How do we test the system? (1) Show the recommendations. (2) If the user clicked on recommended videos.
- Scalability - how to handle growing amount of data
- How many read queries per second?
- Average user watches 1 video per day and 40 million active daily users. 40 million requests/day. 40 million requests / (24 hours 60 min 60 sec) ~= 500 requests/second
- How many write queries per second regarding the user interaction about the recommended videos? 10 million writes/requests per second
- Can there be spikes in traffic?
- Yes, 50 million active users with 2 average movies per person = 100 million movies / day = 1100 read requests/second
- Performance - how fast
- What is expected data fetching delay? How long should a user wait until seeing the next video? 10 seconds max
- What is expected p99 latency for read queries? 5 seconds
- Reliability The system should continue to perform the correct function at the desired level of performance even with (hardware or software faults, and even human error). And ML systems can fail silently.
- How do we know if recommendation is wrong if we don't have ground truth labels to compare it with? We can just monitor how often users use recommendations.
- How often do we have to meet SLA requirements? We have to meet 1 second requirement 95% of the time.
- Cost - budget for the system
- Should the design minimize the cost of development? Yes
- Should the design minimize the cost of maintenance? Yes
Functional requirements
- Recommendation is generated from similar videos and user history of previous engagement. (TODO?)
- Each movie will have a set of thumbnail images, videos in different formats, subtitles.
Non-functional requirements
- Scalable 80 million American users and 40 million daily active users
- Highly performant less than 1 second of recommended video retrieval
- Highly available survives hardware/network failures, no single point of failure
- Consistency
- If the model prediction takes too long, then there should be something to fall back on such as reverting to a precomputed result.
APIs
The system has to compute a list of recommended movies.
computeRecommendedMovies(userId, options?)
The system has to return a list of recommended movies.
getRecommendedMovies(userId, options?)
- userId (GUID): the id of the user who is fetching recommended videos
- The optional options parameter can contain the following fields:
- afterPostId (GUID): fetch the recommended videos from after this video. If unspecified, fetch the newest recommendation.
- count (number): the maximum number of videos returned for each request. If unspecified, some default maximum number is set by the backend.
- The return values is a JSON containing a list of news feed items.
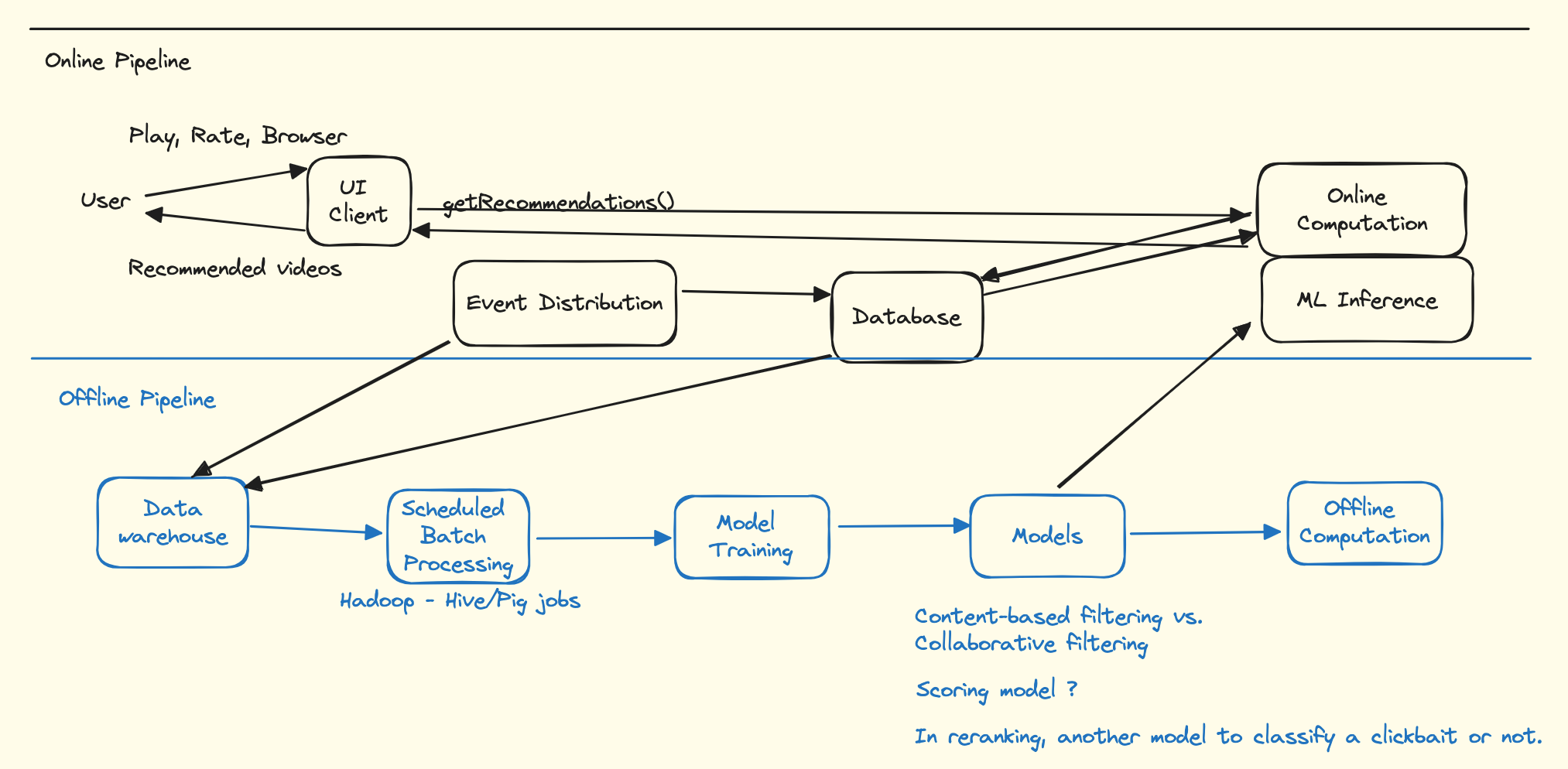
High level architecture
Starting point
| Kinds | Description of jobs | Pros | Cons |
|---|---|---|---|
| Online | Responds to requests in realtime | Can respond better to recent events and user interaction | SLA requirements lead to limited computational complexity and the amount of data to be processed |
| Offline | No realtime, batch jobs | Relaxed time requirements (No SLAs) | Data and computation results can grow stale |
| Nearline | oneline-like computations but do not require them to be served in real-time | --- | --- |
What to store
Individual event vs aggregated data in real-time
- Here, individual event means user A wants feed populated as well as user B, user C, etc. Aggregated data means we can aggregate the user A, B, and C their requests to populate their feed.
- Individual event includes timestamp, country, device type, operating system, etc.
- When we aggregate data, we calculate a total count per some time interval (e.g. 1 minute) and we lose details of each individual event.
Inidividual events and aggregated data are not a matter of REST API or eventbus. It's just a matter of what you are sending. It's what and when you send it. It's not how you send it. Aggregating events can happen on a individual level or multiple invidivudal levels. Aggregation comes with a cost of losing some information. It's just a matter of fast read vs fast write.
| --- | Invidividual events | Aggregated data |
|---|---|---|
| Pros | (1) Fast writes (2) Can slice and dice data however we need (3) Can reclaculate numbers if needed. | (1) Fast reads (2) data is ready for decision making |
| Cons | (1) slow reads (2) Costly for a large scale (many events) | (1) Can query only the way data was aggregated. (2) Requires data aggregation pipeline. We need to pre-aggregate data in memory before storing it in the database. (3) Hard or even impossible to fix errors |
- Ask the interviewer about the expected data delay: time between when the event happened and when it was processed. If the latency is no more than several minutes, we must aggregate data on the fly (stream data processing). If several hours are okay, then we can store raw events and process them in the background (batch data processing).
Where we store
Processing Service
Offline Service
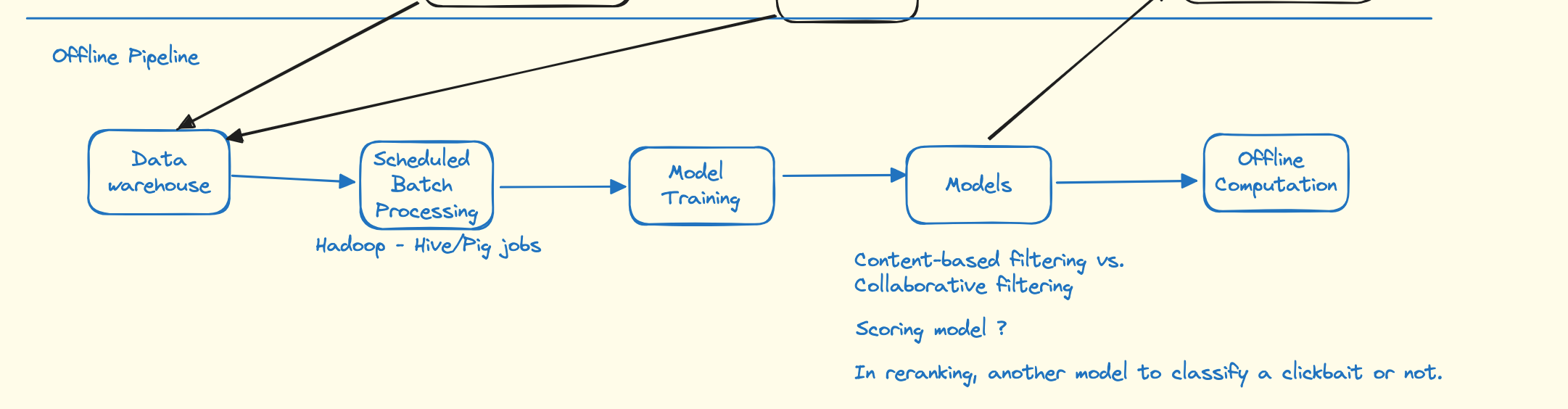
- More choices in algorithmic approach such as complex algorithms and less limitations
- Support rapid experimentation
- No strong latency requirements
- Not react quickly to changes in context or new data.
- Requires infrastructure for storing, computing and accessling large stets of precomputed results
Online Service
- Service Level Agreements (SLA) that specifies the maximum latency of the process in responding to requests from client applications while our member is waiting for recommendations to appear.
- Harder to fit complex and computationally costly algorithms.
- Purely online computation may fail to meet its SLA in some circumstances.
- Various data sources involved need to be available online.